Security Best Practices for AWS Lambda

by Valts Ausmanis · July 18, 2024
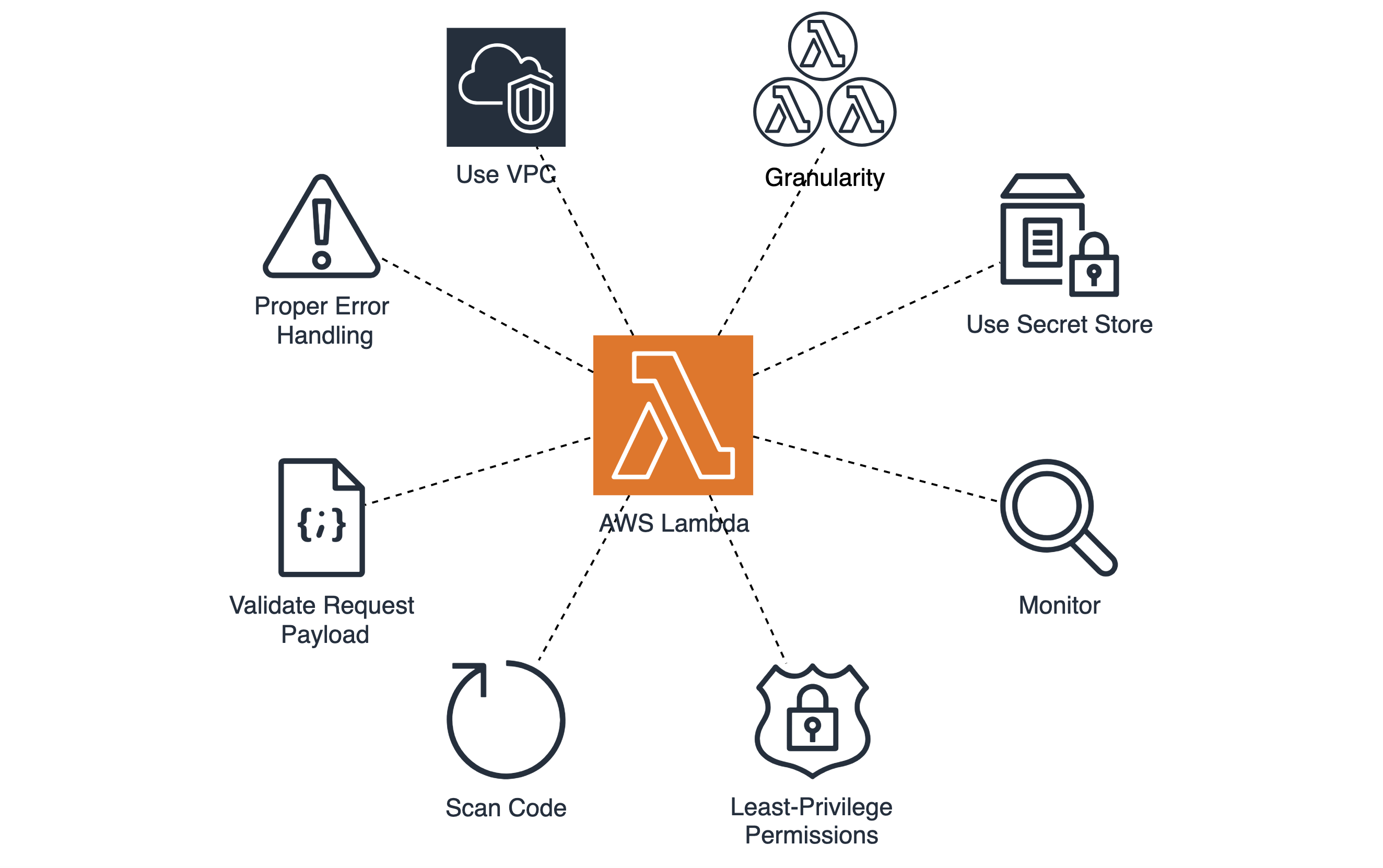
AWS Lambda accelerates new application development by allowing product teams to focus on actual business values rather than spending a time maintaining and operating underlying infrastructure. While AWS manages all the foundation services and underlying infrastructure, you are still responsible for the code you write to operate your product’s business logic and configuration of Lambda functions. I have created a useful list of best security practices with practical examples to help you to improve the security of your AWS Lambda functions.
In This Article
- What is AWS Lambda?
- What is AWS Shared Responsibility Model?
- Security Best Practices for AWS Lambda
- Develop Task-Specific Lambda Functions
- Use a Single Least-Privilege IAM Role per Lambda Function
- Lambda Functions Shouldn’t Have Public Access
- Enable Data Logging
- Implement Error Handling
- Validate Request Payload
- Store Secrets Using Parameter Store or Secret Manager
- Deploy Lambda functions in a VPC
- Monitor Your Lambda Functions
- Perform Lambda Code Scanning
- Summary
What is AWS Lambda?
AWS Lambda lets you run virtually any type of application or back-end service without provisioning or managing servers. Additionally, your Lambda functions automatically scale when they receive parallel events, processing each event individually. AWS Lambda supports millisecond metering, and you are charged precisely for every millisecond your code runs.
What is AWS Shared Responsibility Model?
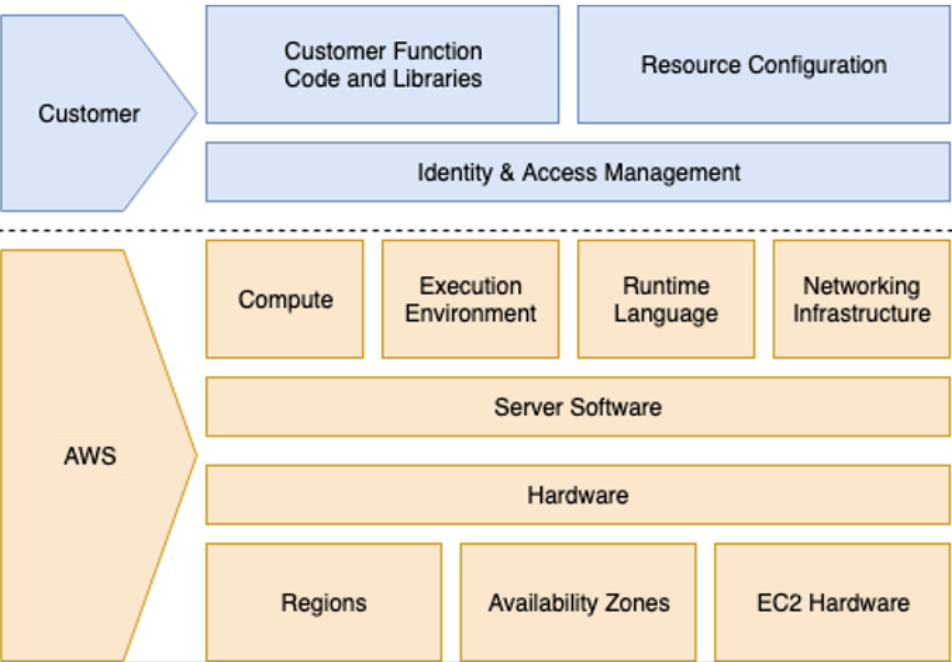
When you use different AWS services, there is a specific shared responsibility between you as a customer and AWS - this is often called the shared responsibility model. This model describes your responsibilities and those of AWS. For AWS Lambda, AWS manages all the foundation services and underlying infrastructure, while you are responsible for:
- The security of your code and any libraries you use
- Lambda function configuration, such as timeout, allocated memory, triggers, environment variables, concurrency, etc.
- IAM-related configuration, such as access roles and policies
Security Best Practices for AWS Lambda
You can create a new AWS Lambda function with a few simple clicks in the AWS console or with a few lines of code using Infrastructure as Code (IaC) tools like the Serverless Framework or CDK. While it’s easy to start using AWS Lambda, there are a few security best practices that I recommend implementing basically for any use case.
Now let’s describe these best practices with practical examples by creating a simple newsletter backend service, which will include the following resources to be deployed to the AWS cloud:
- API Gateway with two endpoints:
- Add new subscriber:
POST /subscriber - Delete subscriber:
DELETE /subscriber/{subscriberId}
- Add new subscriber:
- Two Lambda functions to add and delete our newsletter subscribers
- DynamoDB to store the subscriber data
Develop Task-Specific Lambda Functions
Regardless of whether you are developing your next awesome application or service, it’s important to see the whole picture and split the business logic into multiple groups that define one or several related tasks. These groups can then be transformed into multiple Lambda functions. Having granular Lambda functions will allow you to better maintain, troubleshoot, and monitor your services. This also reduces the attack surface, and in the case that one Lambda function gets compromised, only a small part of the overall functionality could be exposed.
There will likely be discussions within your team about the granularity of these tasks when using Lambda functions. Some will argue that one Lambda function should perform one and only one task, such as “updating user settings,” “deleting a user,” “creating a new user,” or “getting user settings.” Others may suggest splitting the Lambda functions by service. For example, if you have a user management service with simple CRUD operations to create, read, update, and delete users, you might create one Lambda function to handle all these requests.
Regardless of the granularity you choose, remember that one important consideration is that, in the end, you will need to maintain and monitor all these functions. Probably, if you will have thousands of Lambda functions each doing one and only one task will not be the right choice either.
Let’s take a look at a practical example where I will build the newsletter application with two tasks:
- Add a subscriber to the newsletter
- Delete a subscriber from the newsletter
As this is a simple application, I will adopt the approach of having one Lambda function per task and use the Serverless Framework to define and deploy the functions to the AWS cloud:
service: newsletter
functions: # Your "Functions"
subscribe:
handler: src/subscribe.handler
events: # The "Events" that trigger this function
- httpApi: 'POST /subscriber'
unsubscribe:
handler: src/unsubscribe.handler
events:
- httpApi: 'DELETE /subscriber/{subscriberId}'
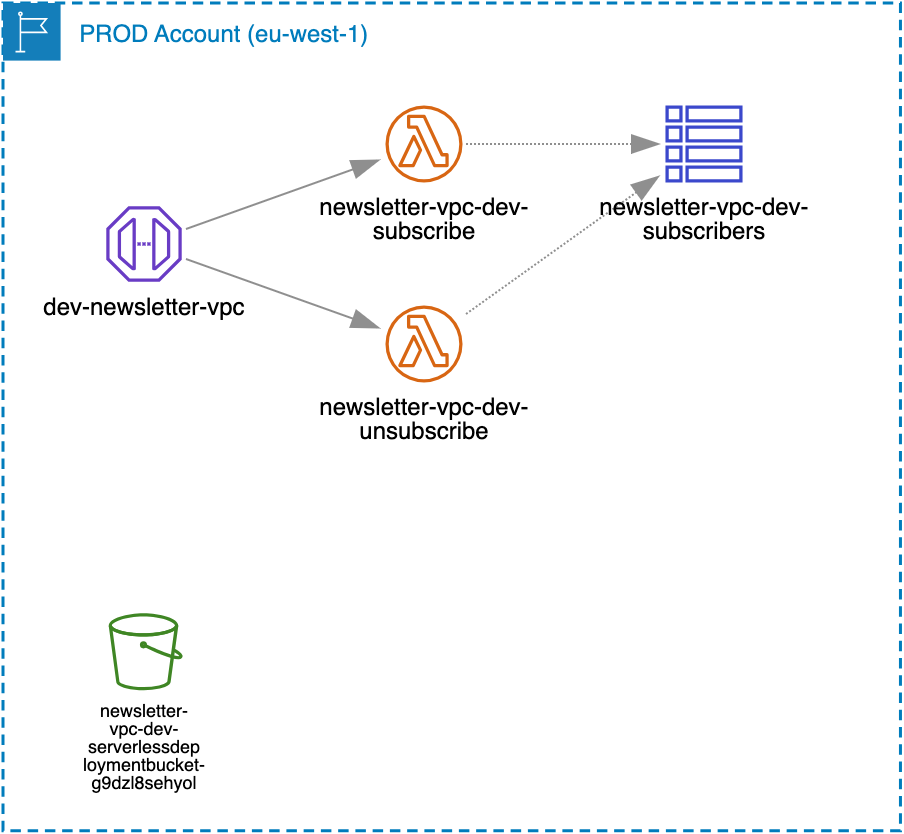
As you can see in the above serverless.yml file that I have split the newsletter business logic into two simple tasks, which translate to two task-specific Lambda functions: “subscribe” and “unsubscribe”. Here is an overview of the newsletter backend service - diagram autogenerated using Cloudviz.io:
Use a Single Least-Privilege IAM Role per Lambda Function
Every Lambda function has an execution role attached to it. This role defines the IAM permissions that specify which AWS services a specific Lambda function can access.
For example, the minimum requirement for every Lambda function is usually access to push execution logs to a CloudWatch log group:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "logs:CreateLogGroup",
"Resource": "arn:aws:logs:eu-west-1:123456789012:*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:eu-west-1: 123456789012:log-group:/aws/lambda/function:*"
]
}
]
}Previously, we discussed why we should develop task-specific Lambdas, where each Lambda is responsible for specific tasks. Similarly, we should define IAM roles and have one role per Lambda function that describes least-privilege IAM access rights only for the tasks it should perform - nothing more. Having one least-privilege IAM role per Lambda function gives us the flexibility to easily add additional IAM permissions to a specific role if needed by not affecting other functions. This approach improves security and reduces the attack surface by limiting the points that an unauthorized user could exploit.
Let’s continue improving security for our newsletter back-end service, where we have two Lambda functions:
- “subscribe” which is responsible to store new subscribers in DynamoDB table.
- “unsubscribe” which is responsible to remove subscribers from DynamoDB table.
As there are two distinct DynamoDB access rights (dynamodb:UpdateItem and dynamodb:DeleteItem) that should be used, we can easily define an IAM role with the appropriate access policy for each Lambda function. Here is example from serverless.yml file:
# The "Resources" your "Functions" use. Raw AWS CloudFormation goes in here.
resources:
Resources:
SubscribeRole:
Type: AWS::IAM::Role
Properties:
Path: /path/
RoleName: 'SubscribeRole-${opt:stage, self:provider.stage}'
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service:
- lambda.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: SubscribeRolePolicy
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- dynamodb:UpdateItem
Resource:
- Fn::GetAtt: [SubscribersTable, Arn]
UnsubscribeRole:
Type: AWS::IAM::Role
Properties:
Path: /path/
RoleName: 'Unsubscribe-${opt:stage, self:provider.stage}'
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service:
- lambda.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: UnsubscribeRolePolicy
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- dynamodb:DeleteItem
Resource:
- Fn::GetAtt: [SubscribersTable, Arn]
Lambda Functions Shouldn’t Have Public Access
If you grant access to your Lambda functions using resource-based policies to other AWS accounts, it is recommended that you ensure the access policy doesn’t contain a wildcard. For example, the principal element should not be "" or { "AWS": "" }."
Enable Data Logging
AWS Lambda functions are closely integrated with Amazon CloudWatch to send execution logs to specific log groups. These logs usually contain details about when the function was initiated and provide a summary of execution duration, memory used, billed memory, etc.

This information is not really sufficient for troubleshooting if something fails or is not working as expected. That’s why it’s suggested that you perform data logging to have more details for analyzing which part of the code failed and why.
Let’s take our newsletter back-end service as an example and add simple console.log lines (as a quick example) to:
- Log the scenario when email was not provided.
- Log the scenario when an email is successfully added to the subscribed list (DynamoDB table).
- Log Amazon X-Ray tracing headers to be able to query more details about request execution.
if (!email) {
console.log('Email was not provided');
}console.log(`Email was successfully added to the newsletter table with id: ${uniqueId}`)console.log(`X-Ray tracing header: ${process.env._X_AMZN_TRACE_ID}`);By adding data logging (with AWS X-ray tracing enabled) to your Lambda functions, you can see more clearly what happened for a specific request. For example, here are the logs for simple POST /subscriber request to our newsletter backend service without providing the email parameter:
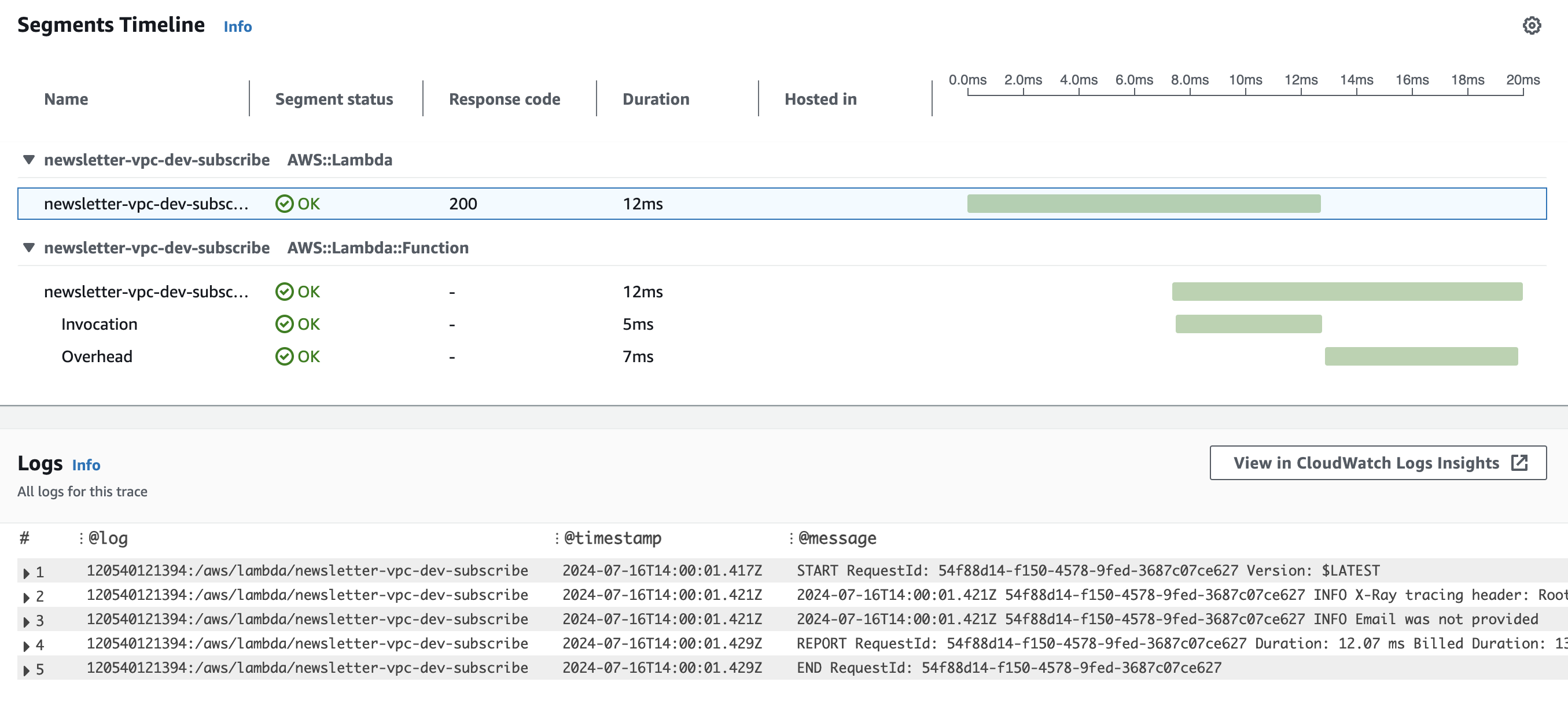
By having detailed logs, we improve our security posture, allowing us to be more proactive and detect when someone is trying to “test” our product's security, enabling us to react appropriately.
Implement Error Handling
As one of our main responsibilities when using AWS Lambda is to take care of the security of our code, proper error handling is a must. There are two main reasons to have proper error handling in place:
- To never expose the actual error message of your code (e.g., containing stack trace details) to your users. Your applications or service users shouldn’t know the actual error or which line of code failed. This basically means errors should be handled gracefully.
- To improve user experience by showing meaningful error messages. Of course, you have to find the right balance between providing just enough and too many details. For example, when users authenticate with a username and password, you most likely shouldn’t return what exactly was incorrect (username or password) but instead send a generic message that
authentication failed, try again.
We can implement simple error handling by using try-catch blocks. Let’s update our newsletter Lambda functions with a try-catch block to handle all unexpected errors:
/**
* Lambda handler to add subscribers to the newsletter
*/
export const handler = async (event) => {
try {
console.log(`X-Ray tracing header: ${process.env._X_AMZN_TRACE_ID}`);
// get email from api request event
const { email } = JSON.parse(event.body || "{}");
if (!email) {
console.log("Email was not provided");
return mapResponse(400, {
message: "Email is required",
});
}
// generate id for the subscriber using timestamp and random number
const uniqueId = Math.floor(Date.now() * Math.random()).toString();
const command = new UpdateCommand({
TableName: process.env.SUBSCRIBERS_TABLE,
Key: { subscriberId: uniqueId },
UpdateExpression: "set email = :email, emailConfirmed = :emailConfirmed",
ExpressionAttributeValues: {
":email": email,
":emailConfirmed": false,
},
});
// add email to the newsletter table
await docClient.send(command);
console.log(
`Email was successfully added to the newsletter table with id: ${uniqueId}`
);
return mapResponse(200, {
subscriberId: uniqueId,
message: "Email subscribed successfully",
});
} catch (error) {
console.error("Error subscribing email", error);
return mapResponse(500, {
message: "Error subscribing email",
});
}
};
The code above is not perfect, but it should gracefully handle most error scenarios, including:
- When no subscriber email is provided.
- When it is not possible to store the email in the DynamoDB table.
- Any other error that occurs inside the try-catch block will be handled as an
Error subscribing emailmessage to users.
Validate Request Payload
When a Lambda function is invoked, a specific event is provided by the service (e.g., API Gateway, S3, SQS, etc.) that invokes the function. We should always validate the request payload (a specific part of the event) before continuing to execute the business logic of our Lambda functions. If the request payload is not in the format we expect, for example, if it is not in JSON, then we should fail the function gracefully.
For example, our previously mentioned newsletter service Lambda functions (subscribe and unsubscribe) are invoked by API Gateway, and the request payload can be found under the event.body parameter. In this example, we are parsing the event.body parameter to get the subscriber’s email. If the body is not in JSON format, this command will fail, and our main try-catch block will gracefully handle the error.
try {
// …
// get email from api request event
const { email } = JSON.parse(event.body || "{}");
// …
} catch (error) {
//…
}Store Secrets Using Parameter Store or Secret Manager
Every application or service will most likely have to handle different kinds of secrets to fulfill specific use cases. For example, connecting to an RDS database, integrating with third-party services, and using API keys or tokens to call their API endpoints.
You should never store these secrets in Lambda function code or as environment variables. While encryption helpers can be used to store sensitive data as environment variables in Lambda functions, I do not recommend this approach due to challenges in sharing them with other functions and difficulties in defining fine-grained access controls.
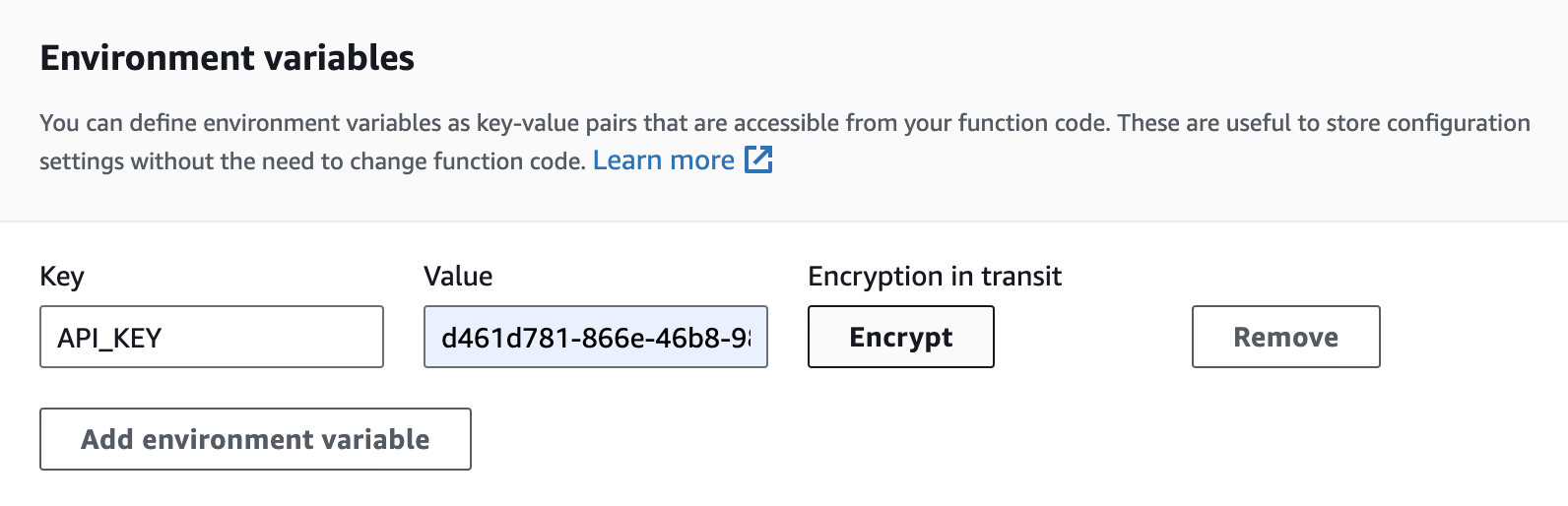
I strongly suggest using a dedicated AWS service for storing and accessing these secrets, such as Systems Manager Parameter Store or AWS Secrets Manager. Personally, I would choose Systems Manager Parameter Store because there are no additional costs for storing and retrieving secrets.
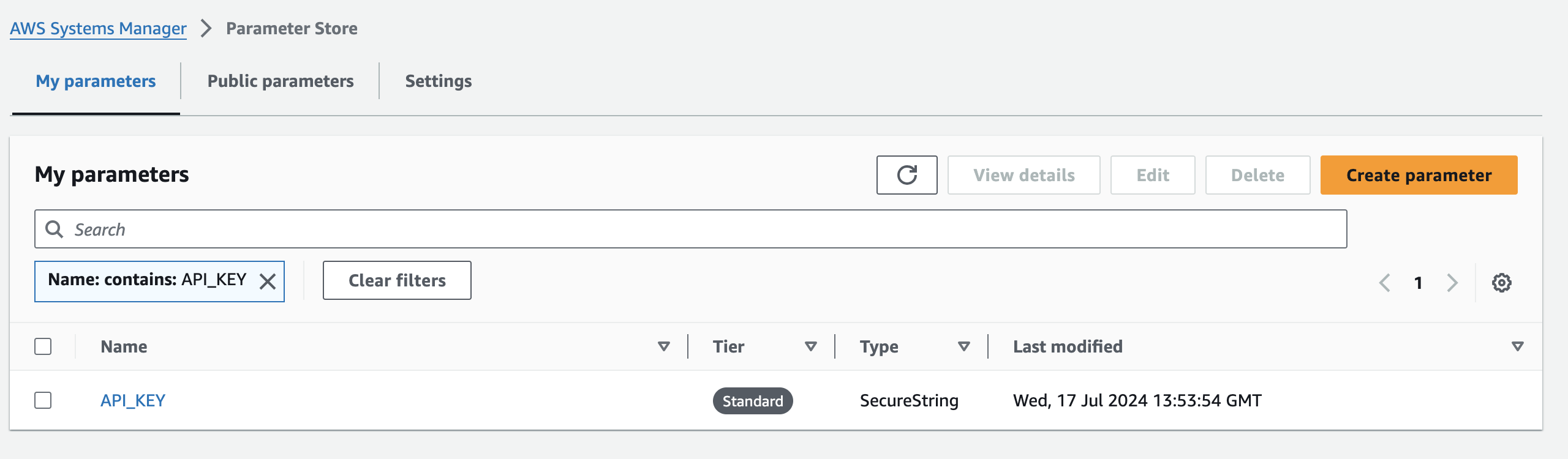
There is only one use case where I would use AWS Secrets Manager, and that is when you need to automatically rotate secrets, for example, changing the RDS password every 90 days.
Deploy Lambda functions in a VPC
When you connect your Lambda function to Virtual Private Cloud (VPC) you improve security for your serverless application so that Lambdas can “talk” to other AWS services like S3, DynamoDB, RDS without requests actually leaving the AWS network (ex. by using VPC endpoints or proper security group configurations).
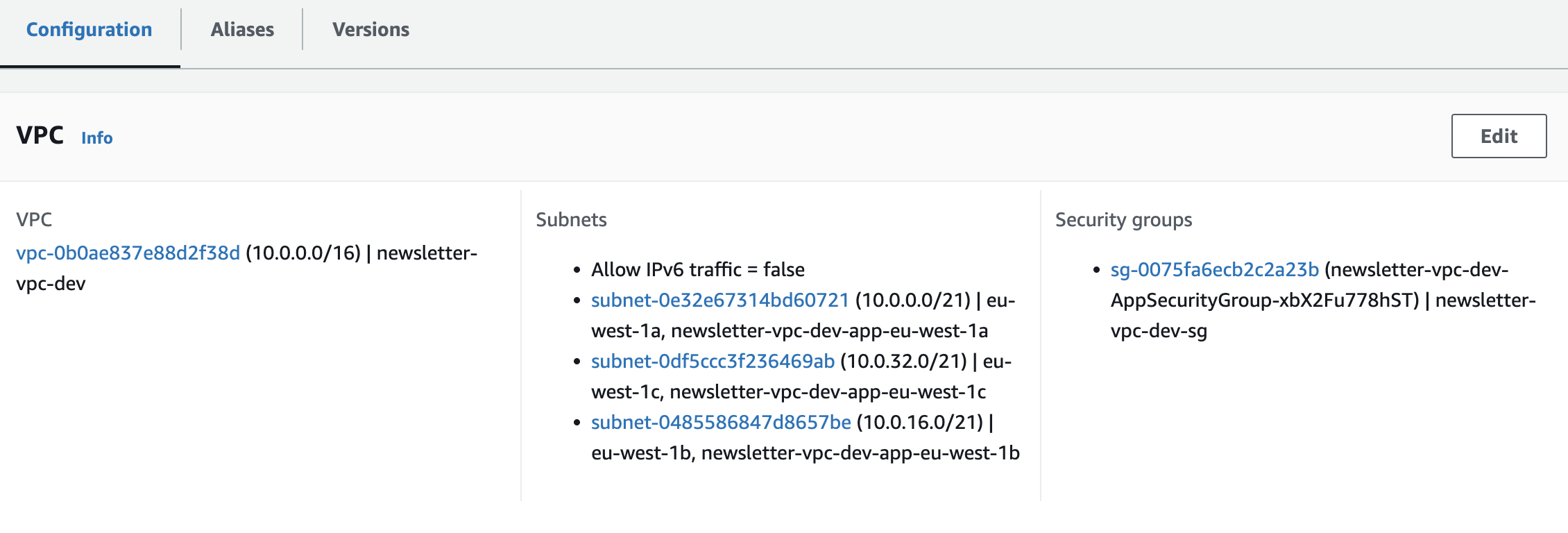
Now, let’s configure our newsletter serverless application to use a custom VPC where our Lambda functions will be deployed. Here is a part of the serverless.yml file that defines our custom VPC and its related resources:
plugins:
- serverless-vpc-plugin
custom:
vpcConfig:
enabled: true
cidrBlock: '10.0.0.0/16'
# if createNatGateway is a boolean "true", a NAT Gateway and EIP will be provisioned in each zone
# if createNatGateway is a number, that number of NAT Gateways will be provisioned
createNatGateway: false
# When enabled, the DB subnet will only be accessible from the Application subnet
# Both the Public and Application subnets will be accessible from 0.0.0.0/0
createNetworkAcl: false
# Whether to create the DB subnet
createDbSubnet: false
# Whether to enable VPC flow logging to an S3 bucket
createFlowLogs: false
# Whether to create a bastion host
createBastionHost: false
# Whether to create a NAT instance
createNatInstance: false
# Whether to create AWS Systems Manager (SSM) Parameters
createParameters: false
# By default, S3 and DynamoDB endpoints will be available within the VPC
# see https://docs.aws.amazon.com/vpc/latest/userguide/vpc-endpoints.html
# for a list of available service endpoints to provision within the VPC
# (varies per region)
services:
- dynamodb
- ssm
# Whether to export stack outputs so it may be consumed by other stacks
exportOutputs: false
We will use the serverless-vpc-plugin, which allows us to configure all the necessary VPC-related resources needed for our Lambda functions to operate within the custom VPC. These include:
- VPC
- Private and public subnets
- Route tables and security groups
- VPC endpoint services to access the DynamoDB table and Systems Manager Parameter Store
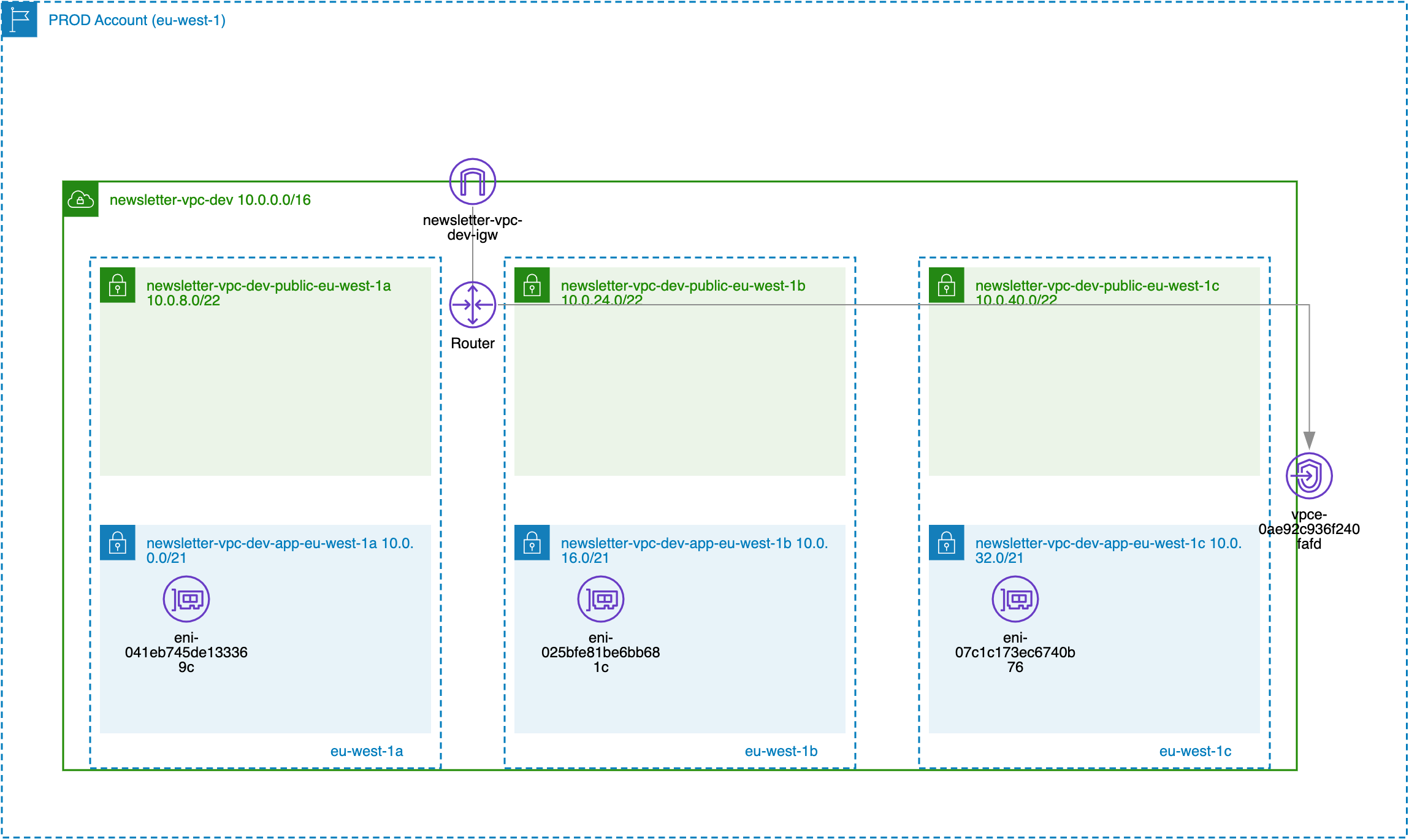
VPC Lambda functions should be deployed across multiple availability zones to ensure high availability .
You can find all the code for the newsletter backend service described previously in cloudviz-io/cloudviz-blog-samples.
Monitor Your Lambda Functions
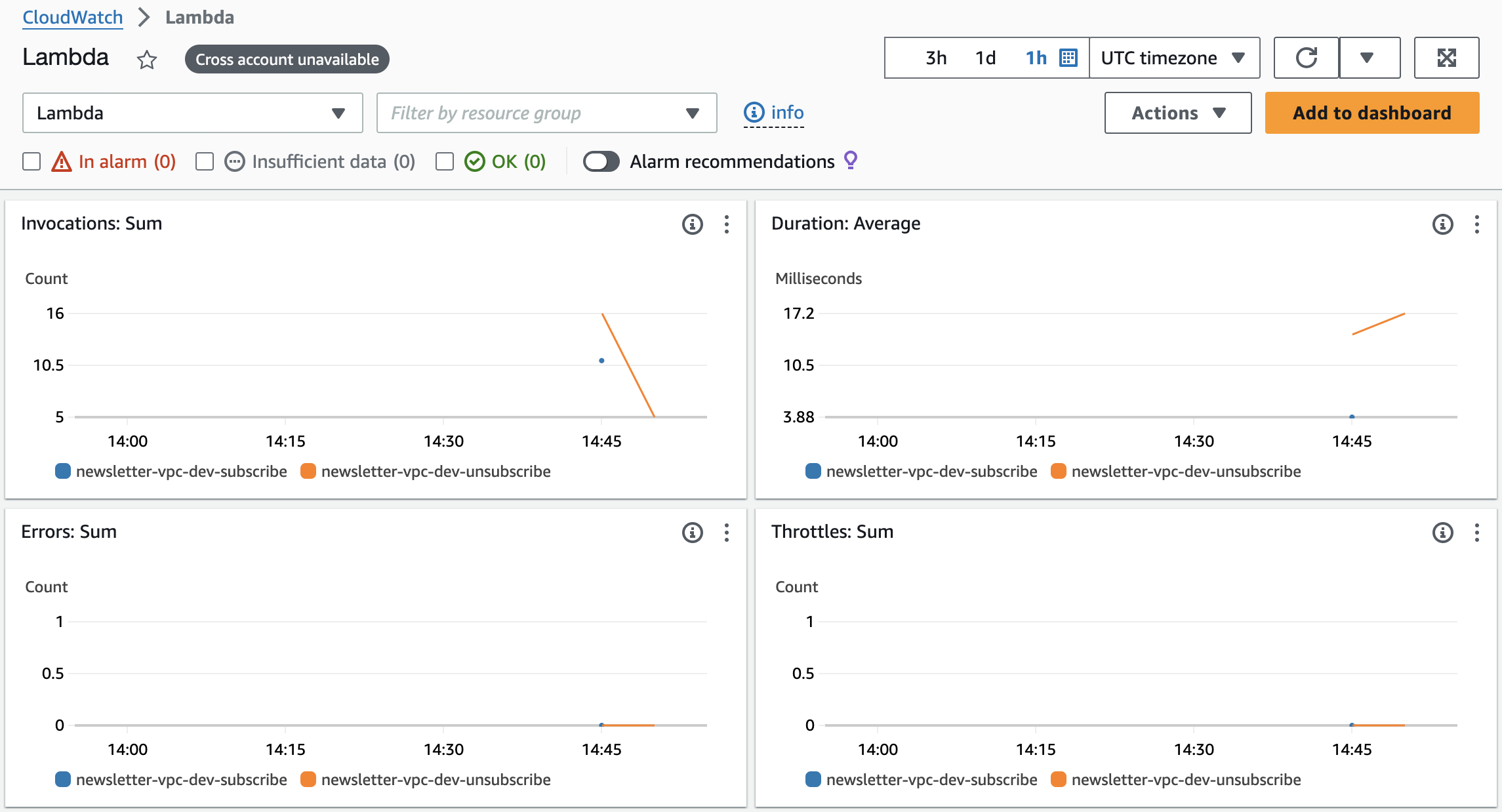
We should always monitor Lambda function availability and performance using CloudWatch. You can easily access the automatically created Lambda dashboard, which will display key metrics like the sum of invocations, average duration, total errors, throttles, etc., for your currently deployed Lambda functions.
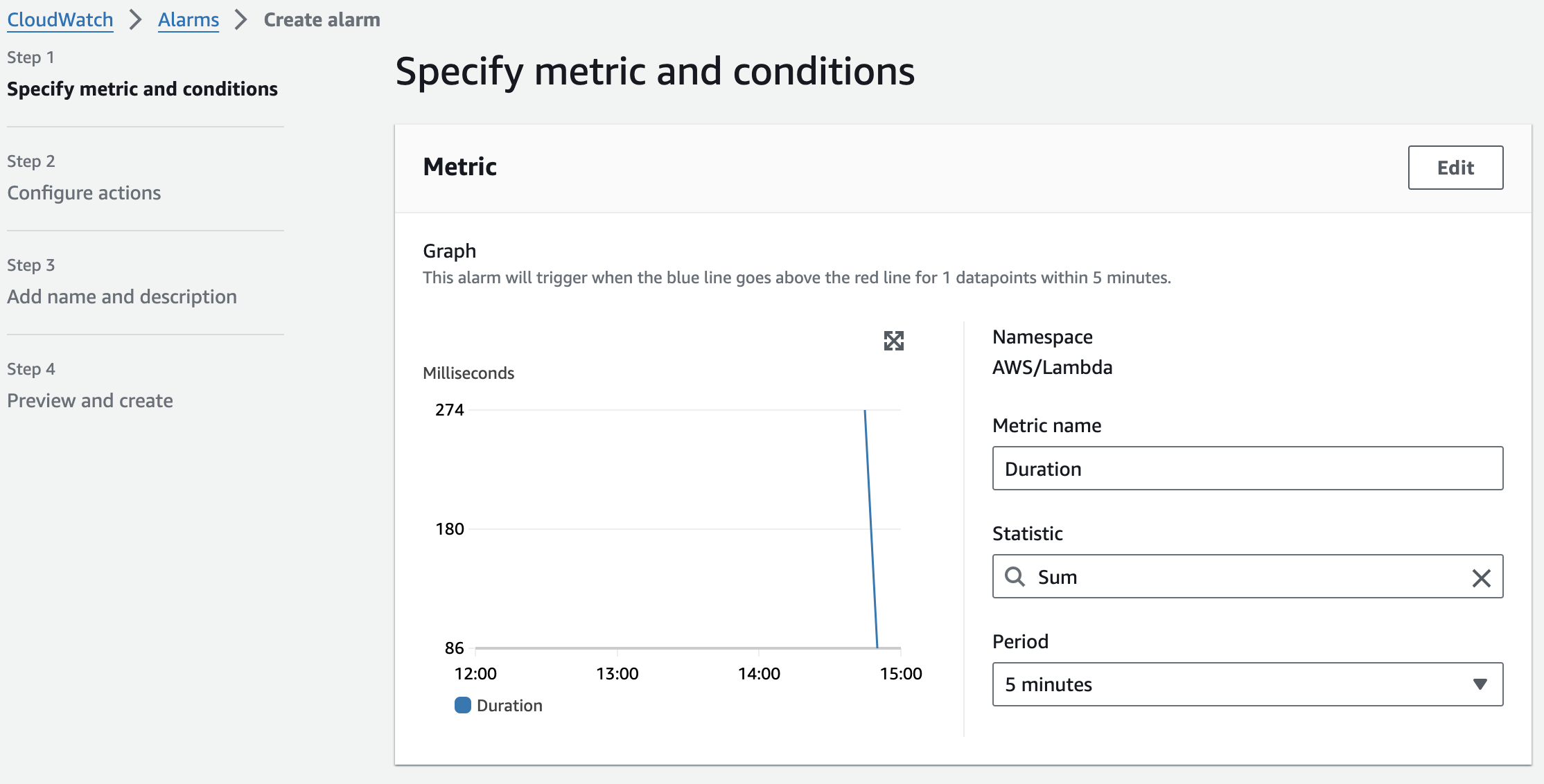
To receive automated notifications (for example, via email or SMS) when certain metrics reach specific thresholds (e.g., total Lambda execution duration exceeds 600 seconds within a 5-minute period or 50 Lambda errors occur within 5 minutes), we can create CloudWatch alarms.
You can go even further by using other AWS services to enhance the security posture of your AWS Lambda functions. For example:
- Monitor your AWS Lambda usage with AWS Security Hub to continuously evaluate Lambda resource configurations against security standards.
- Use Amazon GuardDuty to monitor AWS Lambda network activity logs and identify security issues during the Lambda function invocation process.
Perform Lambda Code Scanning
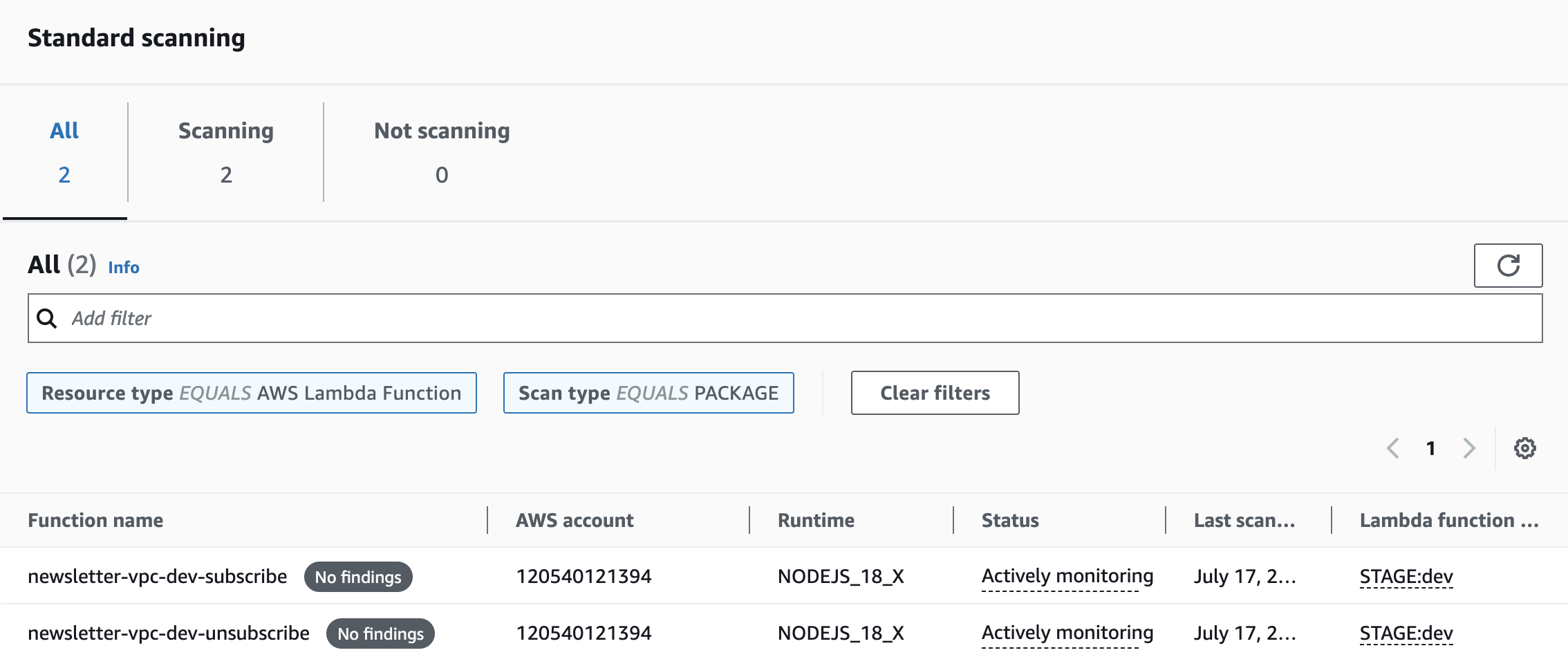
To improve the security of your serverless application, it’s recommended that you scan your AWS Lambda functions for common vulnerabilities and exposures (CVEs). The native AWS approach is to use AWS Inspector for Lambda code scanning. Of course, you can also use various third-party tools, as long as they effectively perform scans and add value to enhance your security.
Summary
We have now explored several best practices for improving the security of your AWS Lambda functions. Remember that this list serves as a solid foundation and starting point in your security journey. As the complexity of your serverless application and code grows, you will need to continuously review and enhance your security configuration and stay updated on the latest advancements in securing your serverless application.
Tired of browsing through the AWS console?
Try out Cloudviz.io and visualize your AWS cloud environment in seconds

As experienced AWS architects and developers, our mission is to provide users an easy way to generate stunning AWS architecture diagrams and detailed technical documentation. Join us to simplify your diagramming process and unleash the beauty of your cloud infrastructure
Support
Contact
Copyright © 2019 - 2026 Cloudviz Solutions SIA